How AI Workflow Automation Actually Works Inside Restoration Operations
AI workflow automation in restoration isn't about chatbots. It's about data moving between systems without manual re-entry. Here's the architecture, the platform paths, and why clarity has to come first.
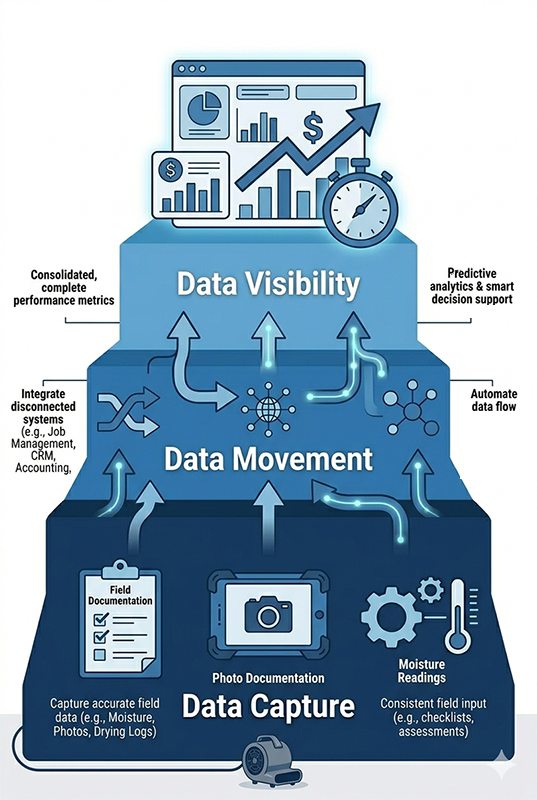
AI workflow automation in restoration connects job management, estimating, documentation, and accounting into a single operational layer, so profitability is visible in real time and nothing falls through the gaps between systems.
At a Glance
Most restoration companies aren't failing at the work. They're failing at the handoffs; the gaps between systems where job data gets lost, re-entered, or never captured at all. AI workflow automation addresses this by connecting the platforms your operation already runs on, creating a data layer that moves information where it needs to go without someone manually carrying it. The result is operational visibility that most restoration owners have never had: live margin by job type, documentation status in real time, and AR aging without a spreadsheet. Getting there requires understanding the architecture before choosing the tools because the wrong build sequence turns an integration project into a maintenance burden that outlasts the problem it was supposed to fix.
Most restoration companies running between $2M and $10M in annual revenue share a common problem: they have more software than they have visibility.
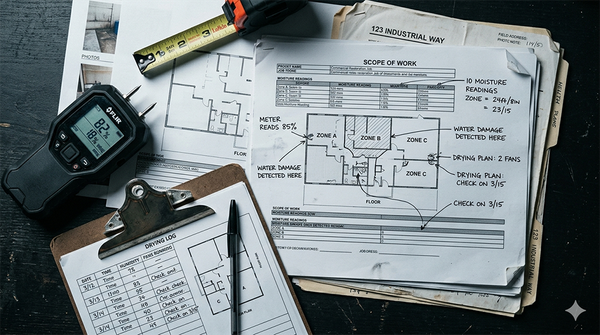
Job management lives in one platform. Estimates get built in another. Field documentation happens in a third. Accounting sits in QuickBooks, largely disconnected from all of it. And somewhere in the gaps between those systems, margin leaks out quietly, through unbilled equipment days, missed line items, scope rewrites that should have been caught at intake, and job costs that don't surface until the work is already done.
That's what this post covers. Not which software to buy, that depends on what you're already running and what your team can realistically adopt. But the architecture underneath the decision: what a connected restoration operation is built from, how data actually moves through it, and what you gain when the pieces work together. Understanding that architecture, what workflow clarity work is designed to produce, is what makes any platform decision a sound one rather than a lateral move.
The Problem Isn't the Tools. It's the Gaps Between Them.
Most restoration companies that struggle with operational visibility aren't under-tooled. They're running five, six, sometimes ten platforms simultaneously, a job management system, an estimating platform, a field documentation app, a CRM, QuickBooks, and a handful of spreadsheets filling in wherever the integrations fall short.
The tools exist. The data exists. What doesn't exist is a reliable path for that data to move between systems without someone carrying it manually.
That gap is where margin disappears. A technician logs drying readings in the field app. Those readings don't automatically populate the drying log in the job file. A PM builds the scope after the job closes instead of during, because the field data wasn't structured enough to build from in real time.
That operational friction is part of a broader pattern the industry has documented. How restoration companies are actually using AI right now, versus where the real leverage is, shapes everything about which automation problems are worth solving first.